首先需要感谢 陈奕帅 学长对整个探索过程的指导与启发。此文权作抛砖引玉,欢迎同学们批评指正、共同探讨!
在 Lab1 课下实现 printk 时,为了对一些 Corner Case
进行测试,我编写了一些测试用例,其中有两句如下:
1 | printk("Min 32-bit = (d) %d; (ld) %ld\n", 0x80000000, 0x80000000); |
出乎预料的是,输出结果分别为:
1 | Min 32-bit = (d) -2147483648; (ld) -2147483648 |
其中有一个值不对!并且,这是一个普遍现象,至少我的室友们,都是这一个输出不对,并且错误的值花样百出。
初步猜测与探索历程概览
为什么我会认为这个问题很是蹊跷呢?有两点:
- 在我们的运行环境中,
sizeof(int) == sizeof(long int),均为 4 字节,也就是%d和%ld是完全一致的,但是它们的行为产生了不一致。 0x80000000和-2147483648的二进制表示应该一致,但是它们的行为产生了不一致。
(1)起初,我认为是 vprintfmt
的实现出了问题,毕竟里面有一个负数取相反数的操作,会不会溢出?(2)接下来,通过初步探索,我认为是
va_arg
出了问题,因为错误的值是从这里来的。(3)但是后来我发现,似乎它没有错,因为当参数被传入函数的时候就已经不对了?(4)然后,我们发现了
C 语言整型字面量的一些
“规矩”,并找到了导致问题的根本原因。(5)但是为啥第二个
-2147483648
对呢?最后的结论与函数传参有关,并且只是一个巧合。
整个效果成因复杂,涉及 C 语言的一些内容,以及参数入栈,变长参数,和内存对齐问题。我觉得整个探索下来收获还是很大的。
关于 gdb 的一些使用技巧(方法)
在很多时候,为了探索一些内容,我们可能需要进行汇编级别的调试,通过键入命令
1 | set disassemble-next-line on |
可以开启,接着,使用 ni 和 si
可以进行类似于 next 与 step
的单步,但是最小单位为一条汇编语句。
为了查看寄存器的值,我们可以使用
1 | info r |
查看全部寄存器的值,此外,也可以通过 $
对寄存器的值进行引用,比如
1 | p/x $sp |
可以分别用十六进制打印栈指针的值,以及 $sp + 4
处的值。
vprintfmt
是无辜的,va_arg 也是
通过在 init.c
上打上断点,可以关注我们想要查看的语句,逐步进入函数,直到我们实现的
vprintfmt 函数,关注这一行:
1 | 86 num = va_arg(ap, int); |
在执行完毕之后,num
获得新值:-2143289512,也就是错误输出的内容,这就初步排除了
vprintfmt 的问题,毕竟 va_arg
拿到的值就不对!
根据一些前置知识,可以了解到变长参数的原理大体上就是参数压栈,然后利用
va_arg 移动栈顶进行读取。既然如此,直接查看 ap
指向的内容也许可以有所发现。于是在刚进入函数时,观察有如下结果:
1 | p/x *(int*)ap # $1 = 0x803fff58 |
啊对,0x803fff58
也就是那个我们一直在寻找的错误值。是不是可以说,函数传参的时候就已经出了问题呢?
参数就这样没掉了?
首先,是找出参数来自于哪里,或者说,ap
地址里的那些值,来自于哪里。
通过查看 printk 入口处的汇编,可以得到一些结论。
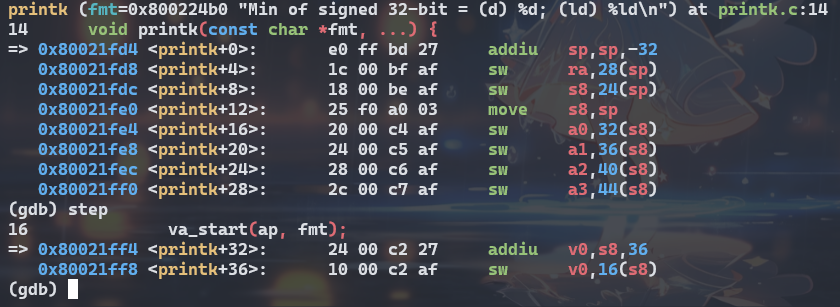
下面,
<+x>表示<printk+x>处的语句,作为简写,对于其他函数同理
<+12> 语句,将当前 $sp 的值记录在
$s8
中,并在接下来的四条语句中,将参数依次压入,此时可以猜测,这是在给
va_list ap 装填参数。

事实上,在执行完 va_start 后,ap 的值与
$sp+36 相同,也就是第一个参数就是 <+20>
处被写入的 $a1,那它是啥值呢?

很幸运,也不幸,恰恰好好是我们的错误值。OK,那么现在的问题是,为啥
$a1 的值不对呢?
如果觉得这里的逻辑有漏洞的话,可以在上面的
num = va_arg(...)那里查看汇编,可以发现就是在这个地址读取的值,也就是现在$a1的值。
解铃还须系铃人,再把目光回到前面,也即调用 printk
之前的操作。

不对啊,我的 $a1 呢???
<+80> 倒是给 $a2
传了一个像模像样的东西,<+84>
又是给谁用的呀?总之,我的 $a1 呢?
不过这倒解释了为啥输出会错,$a1
还是上一个值嘛,错也正常。
蹊跷的 C 语言,蹊跷的整型字面量
好,现在把之前的问题放一放,咱们从一个宏观的视角看一看。也许有同学注意到过,C
语言在定义 INT_MIN 的时候,采用的是
-INT_MAX - 1,而不是简单的写一个
-2147483648,这是为什么?
标准中规定的整型字面量的定义可见 ISO/IEC 9899:TC3 P404 A.1.5
Constants,简单来说,没有 -,也就是说,我们看到的
-2147483648 实际上是一个表达式,是给
2147483648 取了相反数。
这个带来的很重要一点,也就是
sizeof(-2147483648) == 8,根据整型提升的规则,类型应该是
long long int。关于位宽,可以通过打印输出验证。
既然是八字节,那么一个寄存器肯定放不下,于是会被拆两部分:0xfffffff
和
0x80000000,然后又因为是小端存储,高位放在高地址,按顺序是
$a3,也就是 -1,然后
lui a2, 0x8000 也是正确的。
这一下子就符合了上面那张图的压栈内容了!
然后,我们也可以发现,<+64>
开始的四条语句,似乎也是在处理另一个 -2147483648
欸,然后被放在了 $sp+16 那八个字节里面。
内存寻宝与内存对齐
再次将目光回到 printk 入口处的汇编。假设在调用这一个
printk 之前,$sp = \(sp_1\),则进入 printk
函数后,新的 $sp = \(sp_1 -
32\),然后,$a1 至 $a3 分别放在了
$sp + 36 = \(sp_1 + 4\)
开始的 12 个字节(\(+4,+8,+12\))中。
$a0装的是字符串的地址,也即第一个参数

随后,注意到调用之前,<printk_extra_check+72> 与
<+76> 两句,将另外一个八字节的
-2147483648 放在了 \(sp_1+16\) 与 \(sp_1+20\),是不是刚好和上面几个参数接起来了!
也就是说,在压栈的时候,直接跳过了 $a1 与其对应的 \(sp_1 +
4\),这是为什么呢?内存对齐!
因为存储八字节的 long long int,需要内存对齐至 8
的倍数,于是会跳过 \(sp_1 +
4\)。
那么 va_arg 呢?他只知道自己需要读取一个
int,4 字节啊,本来就是对齐的,于是便从 \(sp_1 + 4\)
读了第一个参数,就是那个错误值。接着,从 \(sp_1 + 8\) 读了第二个参数,恰好为
0x800000000,恰好是正确结果!
也就是说,理论上,我们需要使用 va_arg(ap, long long int)
来读取第一个参数,它会检测内存对齐问题,并从 \(sp_1 + 8\) 开始读取八个字节。
做个实验,如果把测试内容改成:
1 | printk("Min %s = (d) %d; (ld) %ld\n", "32-bit", -2147483648, -2147483648); |
使用一个字符数组指针作为第一个参数,填充在原先被跳过的那个地方,可以发现输出结果很符合我们的预期:
1 | Min 32-bit = (d) -2147483648; (ld) -1 |
那么这个问题也就得到了初步的解决。
结语
整个原理看上去还比较简单,就是把几个小知识点组合在了一起(除了那个比较鲜为人知的整型字面量问题),但是整个探索的过程还是比较有趣的。
尤其是经历了震惊、冷静、怀疑编译器、初见端倪再到豁然开朗的过程,那就更有趣了,不是吗?
欢迎各位同学发表自己的看法与见解,大家一起讨论!
最后修改于:
最后回复于: